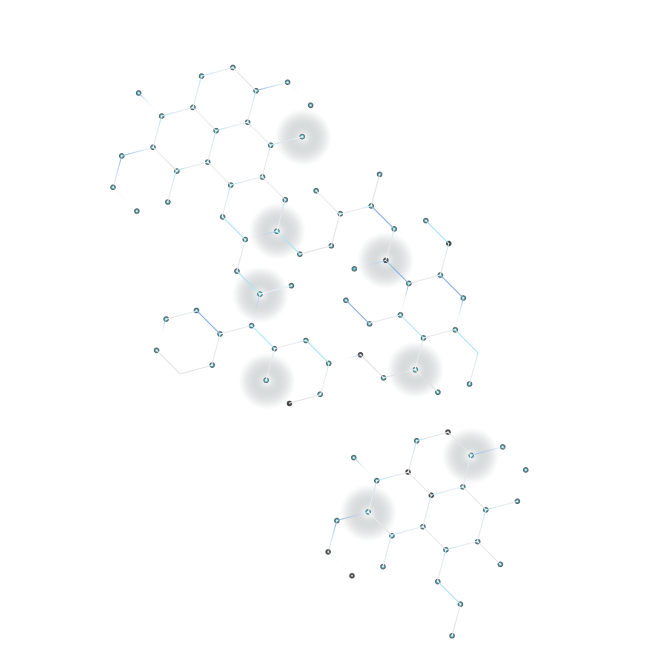In computer science, the term of availability is used to describe the period of time when a service is available. High availability is a quality of a system that assures high-level performance for a given period of time.
The main goal of high availability is to eliminate the Single Point of Failures (SPoF) in your infrastructure. To eliminate SPoF, each layer of your stack must be prepared for redundancy. Be aware, redundancy alone cannot guarantee high availability. A mechanism must detect the failures and take action when one of your components of the stack becomes unavailable.
Availability is usually expressed as a percentage of uptime in a given year. The following table shows the downtimes (when the system is unavailable) for a given availability percentage.
|
Availability % |
Downtime per year |
Downtime per month |
Downtime per week |
Downtime per day |
|
90%
|
36.5 days |
72 hours |
16.8 hours |
2.4 hours |
|
99%
|
3.65 days |
7.20 hours |
1.68 hours |
14.4 minutes |
|
99.9%
|
8.76 hours |
43.8 minutes |
10.1 minutes |
1.44 minutes |
|
99.99%
|
52.56 minutes |
4.38 minutes |
1.01 minutes |
8.64 seconds |
|
99.999%
|
5.26 minutes |
25.9 seconds |
6.05 seconds |
864.3 milliseconds |
The main question is: what system components are required for high availability? High availability depends on many factors such as:
If your stack contains a Single Point of Failure from one of these factors, then your stack is not highly available (as much as you want). Each layer of a highly available system will have different needs of software, hardware, and configuration, so let’s check them out.
Each datacenters site has the same service deployed, but it is responsible for serving only the requests from their geographical area. All datacenter are independently fault-tolerant, but if one of them is going down for any reason, then the failure mechanism will redirect the requests to another datacenter. It will be slower or more expensive, but it is better than a completely unavailable service.
How can you detect the failure and make your structure (request redirects) independent from this? You need to make sure your local balancers survive the data center failure. You can use a simple DNS round-robin technique (but we do not recommend it), open source load balancers (such as haproxy or Nginx), or paid services (Nginx Plus). A simple and useful technique is that you just host the load balancers somewhere close to the users and keep it isolated from the data center. You can use the load balancers in an Active/Active, Active/Hot Standby or an Active/Passive formation.
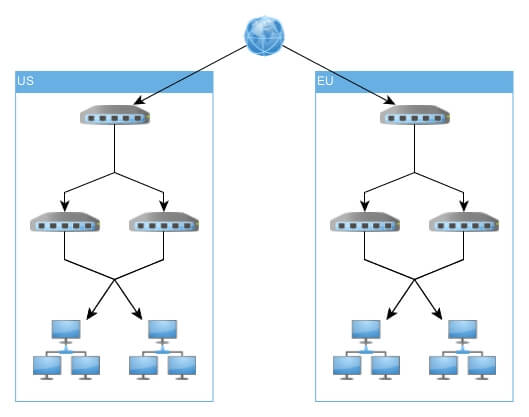
What is another meaning of high availability? The ability to define, achieve and sustain target availability objectives across services and/or technologies supported in the network that aligns with the objectives of the business.
The most important factor is cross-connected dual-core networks. Why two core networks? Full redundancy allows one of them to be taken out of service for maintenance, while production continues on the other one. Dual-core redundancy is important for companies that can no longer afford maintenance windows.
You can use multiple network routing techniques to achieve network resilience, such as BGP (Border Gateway Protocol) to exchange routing information between autonomous systems, IS-IS (Intermediate System to Intermediate System) or OSPF (Open Shortest Path First) to move routing information within computer networks.
You can achieve high availability for networking without high-class equipment if your main goal is fault tolerance and not performance. You can use VRRP (Virtual Router Redundancy Protocol) for an automatic assignment of available IP routers to participating devices/hosts. The protocol is described in RFC 5798, but Cisco made a similar protocol with essentially the same functionality which is patterned and licensed.
You can find several solutions for high-availability systems created by different vendors (Cisco, IBM, HP), but if you want to achieve this in a Linux/Unix based routing system, you can use Pacemaker and Corosync/Heartbeat for this task.
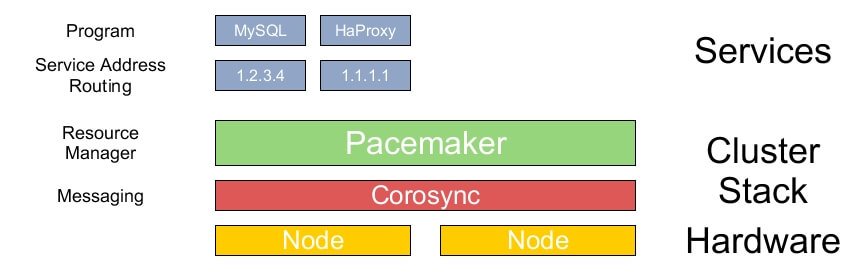
Single components (server/switch/router) have Single Point of Failures too. Imagine that you have a server with only one power supply. Do you think is it highly available based on the energy consumption? The server has only one CPU socket, or it is only handled non-ECC RAM modules. Is it highly available? Redundant? The answer to the questions is no. (We have more examples if you want).
On the hardware level, you want to check a lot of components in your device to be sure about its high availability, such as:
Data loss and inconsistency can be caused by several factors, but one of the most important is disk failures. Highly available systems must account for data safety at any level.
You can achieve high availability for data in many level:
It you want data consistency first, then the different RAID levels can help you, or if you have a lot of cheap server then you can try with clustered filesystems.
If your applications depend on performance or availability, then you can take a chance with application level solutions for scalability and load balancing.
We wrote a few things about the high availability application, so let’s summarize it:
If you want a fault tolerant, highly available application system, then you must check application’s design and architecture, because it’s important how the application handles the failures of different components.
We recommend reading some articles about microservice architectures, especially if you have a high workload application, so check out our blog post about it1. But if you want to learn more about it, then take a look at reactive architecture too.
As you can see, many of the components aren’t able to do well on their own, but if you pay attention for only a few (or building on each other) components, then you can achieve a more highly available architecture &system.